A seguinte mensagem é a sétima comunicação da série Perguntas Frequentes
em Bioestatística, da autoria de membros do Laboratório de Bioestatística e
Informática Médica da Faculdade de Medicina da Universidade de Coimbra. Pretende-se
fomentar uma discussão sobre as melhores práticas estatísticas na área da
saúde.
Perguntas frequentes em
bioestatística #7. Como e porquê testar a normalidade dos dados?
Francisco Caramelo e Miguel Patrício
Quando se pretende avaliar ou descrever uma variável quantitativa, é usual
começar-se por aferir se a mesma provém de uma população que apresenta uma
distribuição normal. A verificação da normalidade de uma variável quantitativa
tem impacto tanto na forma como a mesma deverá ser descrita quanto em testes de
hipóteses que se possam realizar.
É usual dizer-se que a distribuição normal (distribuição de Gauss ou
Gaussiana) tem a forma de um sino, Figura
1.

Figura 1. [figura adaptada da entrada da Wikipedia
sobre distribuição normal (2015)] Uma distribuição normal é perfeitamente
simétrica e descrita pela sua média µ e desvio padrão σ. A área total sob a
curva é igual a 1, estando 95% desta área na região compreendida entre as
abcissas µ-2σ e µ+2σ.
Na realidade, não existem populações com variáveis com distribuições
normais, havendo sim alguns casos em que as variáveis têm uma distribuição
aproximadamente normal. Uma forma de verificar a normalidade de uma variável é
pela observação do seu histograma. Na Figura
2 encontra-se representada a pirâmide etária da cidade de Braga em 2008.
Tanto para o sexo masculino como para o sexo feminino, as distribuições das
idades aproximam-se da distribuição normal, não sendo porém inequivocamente
objectivo se se poderá afirmar que as suas idades apresentam distribuição
normal. Na prática e para fins de publicação, é comum recorrer-se a testes à
normalidade, em particular aos testes de Kolmogorov-Smirnov e de Shapiro-Wilk (sendo o último preferível),
para aferir a normalidade de variáveis quantitativas. A
hipótese nula de ambos os testes é que a variável a testar se encontra
normalmente distribuída. Para mais pormenores sobre como usar e interpretar os
testes, bem como os mesmos poderão ser realizados no SPSS, poderá consultar o
documento “Estudo da normalidade no SPSS” (este documento está algo desactualizado pois advogava que nalguns casos se deveria recorrer ao teste de Kolmogorov-Smirnov e noutros ao teste de Shapiro-Wilk. O último teste apresenta quase sempre maior potência, pelo que será preferível usá-lo).

Figura 2. [figura adaptada da entrada da Wikipedia sobre a cidade de Braga
(2015)] Distribuição etária da população de Braga, em 2008.
Na comunidade estatística são apontadas algumas limitações aos testes de
normalidade. Em particular, testes estatísticos como os de Kolmogorov-Smirnov e
Shapiro-Wilk são considerados demasiado sensíveis para amostras de grande
dimensão e pouco sensíveis para amostras de dimensões reduzidas, [1]. Muitos
estatísticos preferem avaliar graficamente a normalidade das variáveis (em
termos de publicação, isto implica representar as mesmas de forma a que os
leitores possam fazer a sua própria avaliação) ou pelo menos sugerem que tal se
faça como complemento a testes estatísticos. A análise de medidas de assimetria
e de curtose é também advogada. Porém, a objectividade e simplicidade dos
testes de normalidade leva a que os mesmos sejam frequentemente adoptados e os
resultados destes reportados, sem recurso a análise gráfica.
O resultado de um teste de normalidade tem implicações na forma como se
deverá lidar com uma variável. Por exemplo, faz sentido falar-se da média e do
desvio padrão de uma variável normalmente distribuída, mas no caso da
distribuição não ser normal é preferível recorrer à mediana e à amplitude
interquartil (diferença entre percentil 75 e percentil 25) para efeitos de
descrição da variável. Também em termos gráficos se aplica este raciocínio: não
faz muito sentido representar-se a média e desvio padrão de uma variável não
normalmente distribuída. Considere-se como exemplo uma variável medida num
estudo num grupo controlo e em pacientes, ver Figura 3. Pretende-se comparar os valores da variável entre os dois
grupos. A análise dos histogramas das idades dos dois grupos, bem como os
resultados dos testes à normalidade, indicam não estarmos perante uma variável
normalmente distribuída.



Figura 3. (cima) – Histograma da variável, para grupo controlo (SW(17)=0.882,
p=0.034) e pacientes (SW(23)=0.880, p=0.010); (meio) – representação gráfica das
idades dos participantes recorrendo a um diagrama de extremos e quartis. Neste
gráfico, as alturas das barras representam as médias das idades dos
participantes e as barras de erro representam erro padrão; (baixo) - representação
gráfica das idades dos participantes recorrendo a um diagrama de extremos e
quartis. Este fornece informação bastante rica quando comparado com o anterior:
para cada grupo pode ser observada a mediana, o primeiro e terceiro quartis e
se existem extremos ou outliers.
Neste exemplo, a representação da média e desvio padrão (ou erro padrão ou
intervalo de confiança) das idades não é adequada, pois remete para a ideia de
simetria da variável e é pouco informativa. Induz ainda em erro, escondendo
diferenças entre os grupos. Note-se que numa distribuição normal, um desvio
padrão tem um significado gráfico muito claro – 95% dos valores encontram-se a
uma distância da média inferior a aproximadamente duas vezes o desvio padrão.
Este já não é o caso se a distribuição não for normal. Será então mais adequado
recorrer-se a outros gráficos, como por exemplo a um diagrama de extremos e quartis
(em inglês, boxplot).
Finalmente, tal como descrito na comunicação Perguntas frequentes em bioestatística #5, os testes estatísticos a
aplicar dependem da normalidade da variável dependente em questão. No caso da
mesma ser normalmente distribuída, poderá recorrer-se a testes paramétricos.
Caso contrário, os testes deverão ser não paramétricos.
FAQ:
1- Que teste estatístico deverá ser usado para verificar a normalidade de uma variável quantitativa quando o tamanho da amostra é inferior a 10?
Nesses casos, opta-se simplesmente por não assumir que a variável se
encontra normalmente distribuída. Como consequência, testes estatísticos que
envolvam a mesma deverão ser não paramétricos.
2- Como se interpreta um diagrama de extremos e quartis?
Na ausência de valores extremos, ou outliers, num boxplot encontram-se representados os valores mínimo e máximo da
variável representada, bem como o primeiro quartil (ou percentil 25, número
abaixo do qual se encontram 25% dos valores atingidos pela variável), a mediana
(ou percentil 50) e o terceiro quartil (ou percentil 75), Figura 4. Denota-se por amplitude interquartil (AIQ) a diferença
entre o terceiro quartil e o primeiro quartil. Valores que distem da mediana mais
do que 1.5 vezes a amplitude interquartil são designados por valores extremos
(ou outliers), sendo representados de
forma individual como um círculo ou uma estrela, dependendo da sua distância à
mediana.
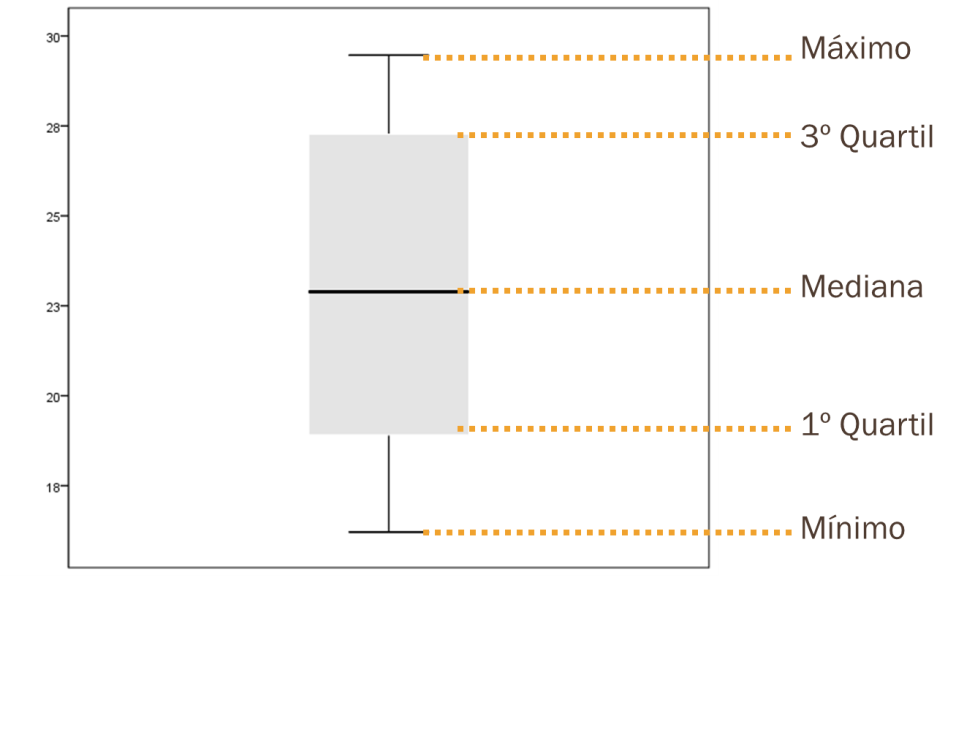

Figura 4. (cima) boxplot sem valores extremos ou outliers; (baixo) boxplot com um outlier.
[1] A. Ghasemi, S. Zahediasl. Normality Tests for Statistical Analysis: A
Guide for Non-Statisticians. Int J Endocrinol Metab. 2012; 10 (2):486-489.
Na próxima edição do Perguntas Frequentes em Bioestatística: “Para
que serve o teorema do limite central?”