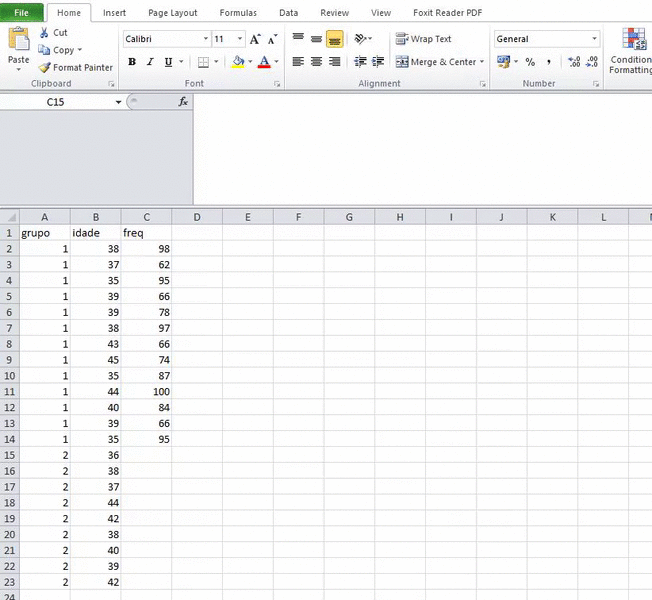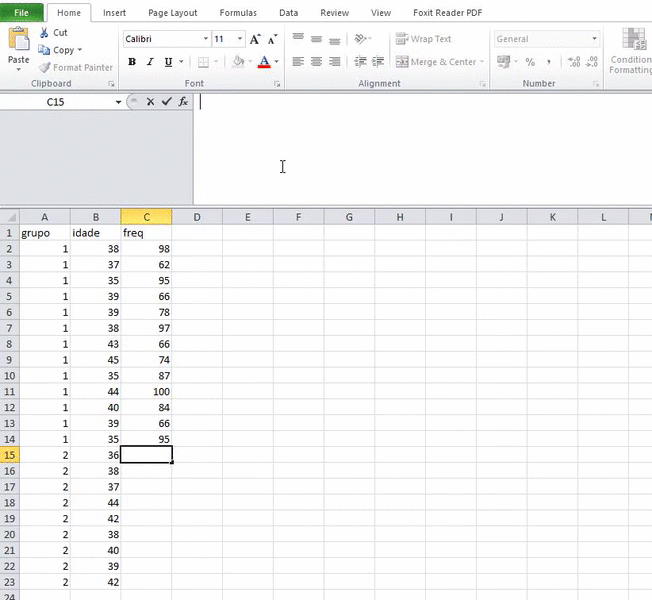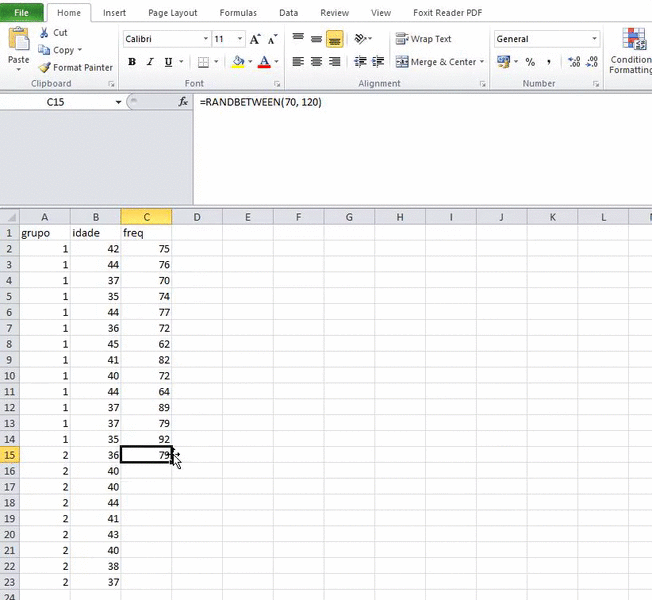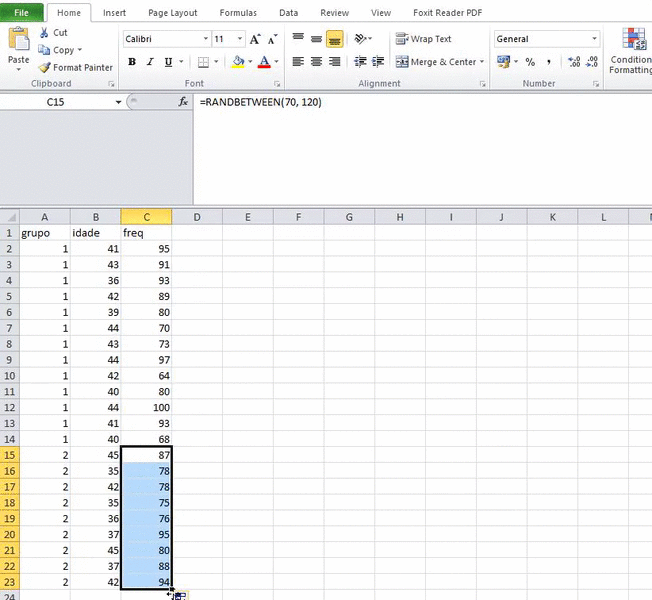
Miguel Patrício e Francisco Caramelo
A investigação científica é, em termos práticos, realizada com base em
projectos que combinados podem levar a uma alteração do paradigma científico, o
que tende a acontecer por acumulação sucessiva de conhecimento. O sucesso de um
projecto científico pode ser medido pela consistência e clareza das suas
conclusões e estas dependem grandemente da forma como este é construído.
Infelizmente, os projectos tendem a ser avaliados relativamente à sua ambição, por
vezes em desprimor do que realmente atingem, levando frequentemente a
construções pouco produtivas ou mesmo estéreis [1]. A elaboração de um projecto
de investigação é pensada muitas vezes de forma imediatista a partir de
problemas que surgem num qualquer estudo prévio, sem haver a devida e atempada
ponderação que garanta resultados efectivamente úteis. Estes constrangimentos
podem porém ser mitigados se se partir do conhecimento dos diferentes elementos
que concorrem para a arquitectura de um estudo antes de se o propôr.
Apesar de existirem inúmeros cambiantes para a estrutura de um estudo de
investigação, é possível identificar alguns elementos em comum e sobre cuja
importância interessa reflectir. Um dos aspectos primordiais é a questão de
investigação, a qual constitui o real motivo do estudo. Note-se que esta é uma
faceta primordial, no sentido de originária, primitiva, pelo que imprime desde
logo, ou não, relevância face ao paradigma científico. A questão de
investigação é então objecto de análise e a forma de a encarar dá origem a
diferentes tipos de estudo. Existem várias taxonomias relativas a tipos de
estudo, sendo geralmente aceite que a variável tempo e a intervenção do
observador conduzem a diferentes planos de investigação. Esta ideia encontra-se
expressa na figura seguinte.
Figura 1
– Tipo de estudos de investigação [2].
A intervenção activa ou a inacção do investigador sobre o objecto de estudo
determina dois tipos de estudos diferentes: estudo experimental e estudo
observacional. No primeiro caso (estudo experimental) o investigador tem um
papel activo impondo, criando, escolhendo e controlando condições diferentes
que determinam a constituição de grupos visando algum tipo de comparação entre
estes. Já num estudo observacional, o investigador limita-se a contemplar de
forma organizada e quantitativa a realidade com que se depara. Embora se diga
que o observador permanece inactivo, tal não é completamente correcto uma vez
que existe sempre selecção dos dados. A forma de selecção das observações é
assim um ponto verdadeiramente determinante para a credibilidade das conclusões,
uma vez que os critérios de inclusão e exclusão das observações podem produzir
vieses desmesurados. Esta é uma razão para que muitas vezes este tipo de
estudos seja desconsiderado relativamente aos estudos experimentais. No
entanto, recorrendo a técnicas validadas de selecção (e.g., aleatorização) as
conclusões são igualmente legítimas, tendo a vantagem de serem estudos menos
onerosos – e frequentemente mais exequíveis - do que os experimentais.
A variável tempo pode ser considerada activamente, quando existem
comparações de variáveis medidas em diferentes pontos do tempo. Pode, ao invés,
não ser considerada no caso em que as comparações são realizadas numa mesma
janela temporal, de forma independente do tempo. No primeiro caso, denominam-se
frequentemente os estudos por longitudinais (alternativamente, temporais) e, no
segundo, por transversais (alternativamente, seccionais). Este tipo de divisão
tem particular importância prática, impactando em aspectos como a inserção de
dados numa base de dados ou o tamanho amostral.
Nos estudos longitudinais o sentido temporal – do presente para o passado
ou do presente para o futuro –, dá origem a duas classificações distintas:
estudos retrospectivos e prospectivos, respectivamente.
Cada área (por exemplo, a epidemiologia) tem especificidades próprias pelo
que, naturalmente, os estudos de investigação apresentam uma estrutura adequada
à mesma. Ainda assim, estes contêm as variáveis anteriormente discutidas, como
se pode depreender do esquema seguinte onde se apresentam diferentes tipos de
estudos epidemiológicos:
Figura 2 – Tipo de estudos epidemiológicos [3].
Um tipo de estudo com particular interesse na área da saúde são os ensaios
clínicos, que têm particularidades estreitamente ligadas ao acto médico que se
reflectem em diferentes pontos do projecto. São disto exemplo conceitos como a
fase de um ensaio clínico (I, II, III ou IV), as hipóteses de investigação
(equivalência, superioridade e não inferioridade) ou as estruturas de
comparação (por exemplo, paralelo, cruzado, em cluster). Estes aspectos
determinam os objectivos, os métodos estatísticos e o tipo de conclusão a que é
possível chegar. A aleatorização e os diferentes métodos de a realizar ganham
singular importância nos ensaios clínicos, na medida em que a intenção de
tratamento se encontra intrinsecamente presente. Estes e outros aspectos
revestem-se de grande interesse mas ultrapassam largamente o âmbito do presente
documento, não podendo ser aqui explorados com a profundidade adequada.
O nome dado ao tipo de estudo a realizar apenas define alguns aspectos
formais do mesmo. É a procura de resposta à questão de investigação que enforma
o estudo científico concomitante, comportando os seguintes elementos
essenciais: a medida principal, a população, a amostragem e o tamanho da
amostra. Demasiadas vezes a atenção do investigador foca-se no tamanho amostral
sem compreender que o número de elementos da amostra é fundamentalmente
determinado pelas características da medida principal. Neste sentido, para o
cálculo do tamanho amostral, a medida julgada principal num estudo é única e deve
ser definida a priori, tendo em conta
algumas características. Em particular, deve ser avaliada sem vieses em todos
os elementos do estudo, ser precisa e exacta e contribuir para que se atinja a
potência estatística adoptada.
Note-se que os estudos são geralmente realizados tendo por base uma amostra
mas com o intuito de obter conclusões válidas para a população. É, assim, de
extrema importância saber qual é a população sobre a qual se está a tirar
conclusões. Apenas depois da definição
da população é possível delinear uma estratégia de amostragem. É crucial que
esta seja de boa qualidade, pois as técnicas estatísticas que permitem a
generalização do que se observa na amostra para uma população em nada ajudam no
caso da amostra se encontrar enviesada (uma expressão tipicamente usada para
descrever os resultados de um estudo mal planeado é Garbage In Garbage Out).
Finalmente, um aspecto que deve ser pensado e discutido na elaboração de um
desenho de estudo são os instrumentos de medida. Estes traduzem uma realidade mensurável
numa quantidade. Por exemplo, a intensidade de luz pode ser medida por um
dispositivo electrónico que transforma a luz em corrente eléctrica. Esta última
é comparada com uma referência, permitindo a sua tradução numa quantidade (genericamente
estes dispositivos electrónicos costumam designar-se por transdutores). Não
havendo instrumentos de medida perfeitos, as medidas resultantes destes últimos
não são livres de erros.
Também num estudo estatístico, os resultados obtidos são uma representação
da realidade, apresentando erros de qualidades diferentes. Deverão distinguir-se
erros sistemáticos de erros acidentais. Os primeiros estão usualmente
associados a calibrações deficientes, fazendo com que o erro da medida mantenha
a sua grandeza independentemente das condições de medida. Diz-se neste caso que
a medida não é exacta, uma vez que se afasta do valor real. Porém, detectando-se
este erro e havendo a possibilidade do mesmo ser medido, pode introduzir-se uma
correcção ao instrumento de medida. Os erros acidentais ou aleatórios têm uma
natureza estocástica cuja dispersão é associada à precisão do instrumento de
medida. Desta forma, um instrumento preciso produz medidas consecutivas muito
próximas entre si. Ou, dito de outra forma, um instrumento preciso apresenta
uma grande reprodutibilidade. Estes erros, não sendo passíveis de serem
evitados, podem ser controlados aumentando o número de medidas.
A noção de resolução de um instrumento de medida também deve ser tida em
conta pelo investigador no momento da comparação entre grupos. A resolução pode
ser aplicada a qualquer natureza de sinal que esteja a ser medido,
consubstanciando-se na capacidade de discriminar dois sinais que estejam
próximos entre si. Um exemplo exagerado seria a tentativa de discriminar dois
pontos à distância de 1 mm com
recurso a instrumento cuja resolução fosse de 1 mm. A mensagem central é que
deve ser conhecido (ou pelo menos estimado) o tamanho do efeito que se prevê
encontrar e, para isso, usar um instrumento de medida com uma resolução
adequada.
[2] Eurotrials, 3Aª, Pedro Aguiar, Catarina Silva, Filipa Chaves, 2005
[3]
http://pt.slideshare.net/FClinico/tipos-de-estudos-epidemiolgicos-26672507
Na próxima edição do Perguntas Frequentes em Bioestatística: “Como
determinar o tamanho da amostra?”