terça-feira, 31 de março de 2020
Role of temperature and humidity in the modulation of the doubling time of COVID-19 cases
Preprint aprovado em 25(02/2020 no MED RXiv com doi provisório (https://doi.org/10.1101/2020.03.05.20031872) a aguardar decisão da PLoS Medicine
https://www.medrxiv.org/content/10.1101/2020.03.05.20031872v1
https://www.medrxiv.org/content/10.1101/2020.03.05.20031872v1
Estimation of risk factors for COVID-19 mortality - preliminary results
Preprint aprovado em 08/03/2020 no MED RXiv com doi provisório (https://doi.org/10.1101/2020.02.24.20027268) a aguardar decisão da BMJ Open
https://www.medrxiv.org/content/10.1101/2020.02.24.20027268v1
https://www.medrxiv.org/content/10.1101/2020.02.24.20027268v1
quarta-feira, 22 de março de 2017
Curso "O que é uma boa questão de investigação?"
Na sexta-feira, dia 31 de Março, terá
lugar o curso “O que é uma boa questão de investigação?”, de acesso
livre, organizado pelo Laboratório de Bioestatística e Informática
Médica (para mais informações:
https://www.uc.pt/fmuc/labbioestatisticainformaticamedica/Cursos).
Este é um curso que poderá interessar:
- a orientadores, a quem cabe ajudar os estudante a definir as suas questões de investigação
Neste sentido, cremos ser útil auscultar a opinião da comunidade. Pedíamos assim que dispendesse 4 minutos do seu tempo, se possível, a preencher o seguinte questionário:
https://goo.gl/forms/etu6gRrJ8xUF8H6u2
Os resultados do questionário serão analisados no curso supra referido.
Este é um curso que poderá interessar:
- a orientadores, a quem cabe ajudar os estudante a definir as suas questões de investigação
- a todos os Professores ou Investigadores
- a estudantes, no âmbito das suas dissertações ou teses de Mestrado ou
Doutoramento - neste trabalho terão forçosamente de definir, de forma
clara, a questão de investigação a que procuram responderNeste sentido, cremos ser útil auscultar a opinião da comunidade. Pedíamos assim que dispendesse 4 minutos do seu tempo, se possível, a preencher o seguinte questionário:
https://goo.gl/forms/etu6gRrJ8xUF8H6u2
Os resultados do questionário serão analisados no curso supra referido.
sexta-feira, 14 de outubro de 2016
Revisões Sistemáticas e Meta-Análises no CINEICC
Hoje o dia de alguns membros do LBIM foi passado na companhia de membros do CINEICC a discutir Revisões Sistemáticas e Meta-Análises. Seguem-se as fotos da praxe.








Big Data
A definição de "big data" não é muito clara. Segundo o quase-omnisciente Google, big data é uma expressão usada para designar "extremely large data sets that may be analysed computationally to
reveal patterns, trends, and associations, especially relating to human
behaviour and interactions." Uma definição que costumamos usar no LBIM é que "big data" são bases de dados tão grandes que o Excel não as consegue abrir.
Em especial na Medicina, big data traz muitas vezes big trouble, como é descrito neste artigo de opinião. Muito do que causa problemas é comum a problemas onde a base de dados não é grande, como por exemplo:
- missing data: quando há variáveis diferentes com missing data, isso poderá diminuir drasticamente o n (tamanho da amostra) do estudo. Havendo três variáveis com missing data cada uma, qualquer teste estatístico que envolva as três variáveis só poderá ter em conta as observações para as quais se tenham observado as três variáveis. A existência de missing data pode transformar tantos dados "normais" quanto big data em insufficient data;
- garbage in, garbage out: quando os dados não são de qualidade, os resultados de uma análise estatística não poderão ser bons. A inclusão de uma variável medida sem precisão suficiente estraga de forma irremediável qualquer modelo, mesmo quando se usa o melhor método nos melhores computadores;
- falta de planeamento: por vezes há a oportunidade de registar dados muito promissores. Porém, a ideia de adquirir dados e depois tentar extrair deles informação interessante, sem um planeamento a priori, é geralmente um passo para o desastre. A ordem correcta do raciocínio deve ser:
- definição do que se quer obter de dados que é possível obter
- definição das características dos dados que é necessário obter (por exemplo, qual terá de ser o sample size? Como deverão ser armazenados os dados para permitir a sua análise)
- obtenção dos dados
- análise
A possibilidade cada vez mais frequente de se obter big data (ou mesmo bases de dados que, não sendo big data, são "grandes" relativamente ao que é comum nalgumas áreas, tendo por exemplo n=300 ou n=400) é aliciante, mas é também terreno fértil para oportunidades falhadas. Colher dados por colher (e depois se vê...) raramente dará bons resultados. O planeamento prévio é essencial.
quinta-feira, 22 de setembro de 2016
Balanço do curso "Investigação Replicável"
Fazendo jus à (recente) tradição de publicar fotos dos nossos cursos, seguem-se algumas. De pouca qualidade, é certo, pelo que se pede indulgência: a sala estava escura para melhor se verem os slides e a câmara era do telemóvel.
Mais importante: tivemos a sorte de poder contar com o contributo precioso dos participantes, que muito agradecemos. Para um futuro (tanto quanto possível) próximo, ficou o compromisso de colocar a discussão do curso num documento.




Resultados do inquérito pré-curso "Investigação Replicável"
Como prometido no último post, tornamos públicos o resultado do questionário sobre Investigação replicável. Os dados em bruto podem ser encontrados aqui.
Analisados os dados no dia 20/09/2016, constatou-se ter havido à data 58 respondentes ao inquérito, dos quais 17 professores, 17 investigadores, 14 estudantes, 10 pessoas com “outra ocupação”. Um total de 51 dos respondentes indicaram ser da área das “Ciências Médicas ou Ciências da Vida”, 2 da área das ”Ciências Sociais” e 5 de outras áreas. Relativamente às idades, 6 indicaram ter menos de 25 anos, 19 ter idade entre 25 e 34 anos, 11 entre 35 e 44 anos, 15 entre 45 e 54 anos, 6 entre 55 e 64 anos e 1 respondente 65 anos ou mais.
De forma porventura pouco surpreendente, os resultados são qualitativamente parecidos aos que haviam sido desvendados num outro inquérito (mais completo e com muitos mais respondentes), da Nature. Incluimos de seguida gráficos onde se pode observar as distribuições das respostas às principais perguntas do noso inquérito:
De forma porventura pouco surpreendente, os resultados são qualitativamente parecidos aos que haviam sido desvendados num outro inquérito (mais completo e com muitos mais respondentes), da Nature. Incluimos de seguida gráficos onde se pode observar as distribuições das respostas às principais perguntas do noso inquérito:




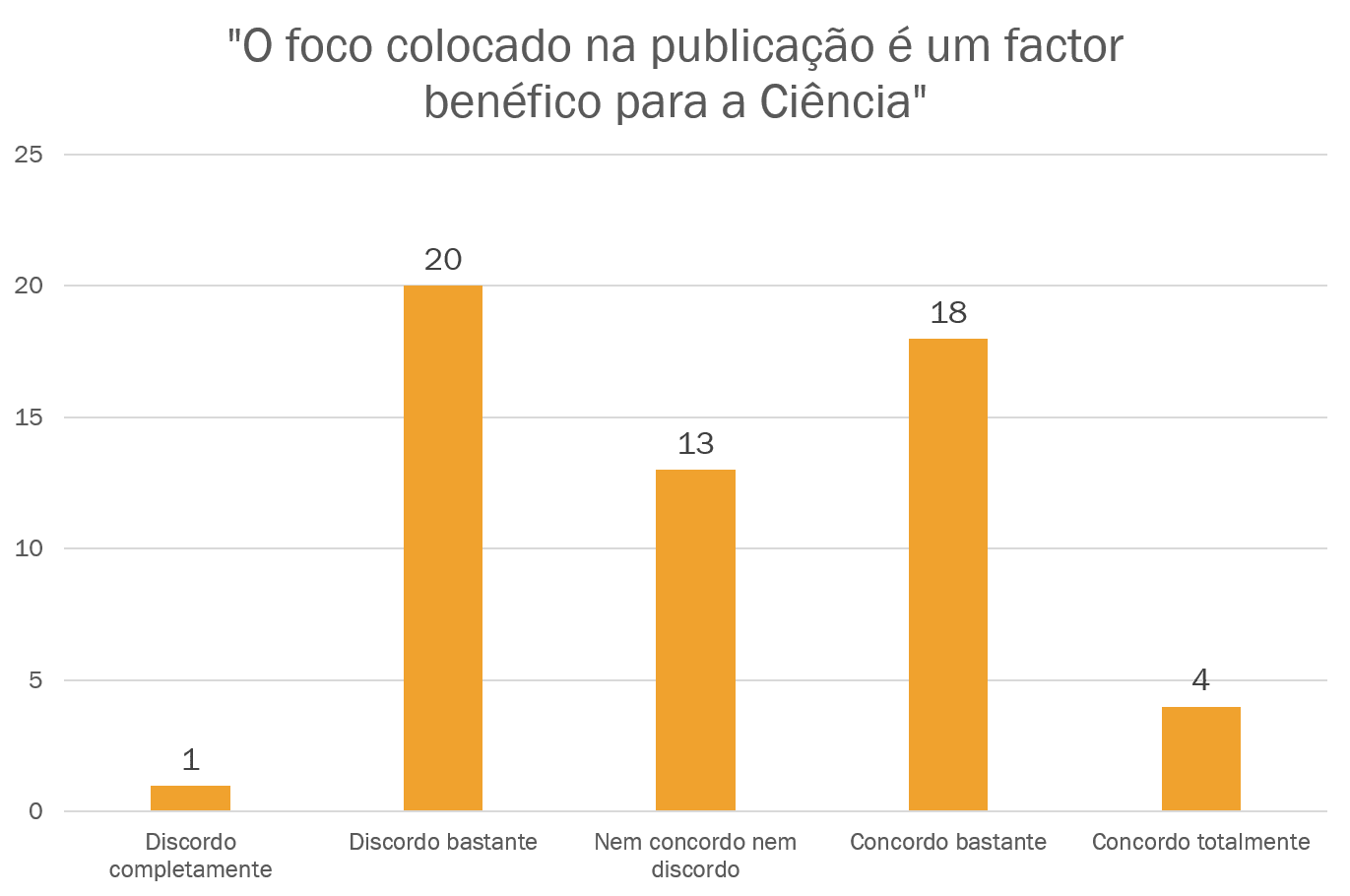





O nosso inquérito foi realizado para iniciar uma discussão sobre a replicabilidade em Ciência, com particular enfoque nas áreas Biomédica, sendo um instrumento informal de recolha de opiniões, sem fins científicos. Ainda assim, cremos que permite tirar algumas conclusões interessantes. Estas e o que tem sido publicado sobre replicabilidade serão objecto de discussão no curso de hoje, "Investigação Replicável". Esperamos em breve ter a oportunidade de glosar as principais conclusões num documento que partilharemos aqui.
segunda-feira, 12 de setembro de 2016
Replicabilidade em Ciência

O Laboratório
de Bioestatística e Informática Médica (LBIM) da Faculdade de Medicina da
Universidade de Coimbra irá organizar, no dia 22 de Setembro, o curso “Investigação Replicável”, no qual se pretende discutir o que funciona, o que falha e como
melhorar para garantir replicabilidade dos estudos científicos. Será colocado
um particular enfoque no papel da Bioestatística. O curso é aberto a todos os
interessados, solicitando-se apenas, motivos logísticos, que seja efectuada uma
inscrição. Como prelúdio ao curso, pedimos ainda o preenchimento de um breve
questionário, cujos resultados darão mote à discussão e serão posteriormente
apresentados no blog do LBIM.
Nota: Houve uma alteração da sala onde irá decorrer o curso, passando a ser o Anfiteatro 1 da sub-Unidade I da Faculdade de Medicina (pólo III)
Nota: Houve uma alteração da sala onde irá decorrer o curso, passando a ser o Anfiteatro 1 da sub-Unidade I da Faculdade de Medicina (pólo III)
sexta-feira, 15 de julho de 2016
Ano lectivo 2015/2016 a chegar ao fim
Com a realização hoje do último dos cursos LBIM do segundo semestre do presente ano lectivo, chega o tempo de fazer um pequeno balanço.

O ano de 2016 tem permitido a implementação de grandes mudanças no Laboratório de Bioestatística e Informática Médica (LBIM):
- Começámos este ano a estruturar os cursos que oferecemos (abertos a toda a comunidade) numa estrutura coerente: os cursos LBIM2016. Até hoje já decorreram 10 desses cursos, estando ainda previstos 4 cursos entre Setembro e Dezembro de 2016: Investigação Replicável, Análise Factorial e Análise de Clusters, O problema das comparações múltiplas e Classificação Estatística. Sendo certo que serão proximamente divulgados os cursos LBIM2017, ainda estamos em discussões internas sobre o seu formato.
- Iniciámos este ano a leccionação de novas Unidades Curriculares. Uma destas, "Métodos de Investigação I : Planeamento de Trabalhos Experimentais e de Dissertação", leccionada em ambos os semestres aos 4º e 5º anos do Mestrado Integrado em Medicina, permitiu fornecermos um apoio estruturado a alunos na fase em que estão a trabalhar nas suas dissertações de Mestrado. Para o LBIM, a inclusão desta Unidade Curricular opcional no plano do Mestrado Integrado em Medicina foi uma pequena revolução. De facto, há todos os anos muitos alunos da FMUC que pedem ajuda a membros do LBIM para a análise estatística dos dados das suas dissertações. No passado, essa ajuda era muitas vezes prestada de forma informal e quando possível, sem uma estrutura clara e em detrimento das demais actividades dos membros do LBIM, não sendo contabilizado na sua produção científica ou pedagógica. Neste momento, para além da possibilidade (quando faça sentido) que todos os alunos têm de serem orientados ou co-orientados por membros do LBIM, os alunos do Mestrado Integrado em Medicina podem inscrever-se na Unidade Curricular "Métodos de Investigação I : Planeamento de Trabalhos Experimentais e de Dissertação". Nesta pretende-se que os alunos adquiram todas as ferramentas para realizarem de forma autónoma toda a análise estatística dos seus dados - o acompanhamento é próprio, mas exige-se essa autonomia.
- Temos procurado eliminar o trabalho informal realizado por elementos do LBIM. Procura-se assim libertar um bem escasso essencial - tempo! - bem como aumentar indicadores de produtividade como orientações ou artigos publicados.
Naturalmente, todas as mudanças são ancoradas na continuidade da filosofia em que nos baseamos: procuramos ir para além da Estatística, defendendo as boas práticas que decorrem da correcta aplicação do método científico. Procuramos ainda ter a abertura que acreditamos dever caracterizar todos os grupos de investigação, sendo essa uma das razões pelas quais tentamos organizar um número grande de cursos e manter em funcionamento este blog. Temos como objectivo (reconhecidamente ainda pouco conseguido) a implementação de uma discussão activa sobre bioestatística e, de forma mais geral, como melhorar a investigação que é feita presentemente. O próximo curso que organizaremos, "Investigação Replicável", propõe-se discutir isso mesmo: qual é o estado da Ciência e como fazer melhor Ciência? Adicionalmente, não faltam ideias sobre os passos a seguir pelo LBIM para atingir o objectivo de dinamizar uma discussão mais profícua que envolva toda a Faculdade de Medicina e demais comunidade: esperamos ter novidades em breve.
Todas as sugestões, críticas ou comentários que nos possam deixar serão muito apreciadas.
Todas as sugestões, críticas ou comentários que nos possam deixar serão muito apreciadas.
quinta-feira, 14 de julho de 2016
Lying with statistics
Qual a melhor medida descritiva? Média, mediana, mínimo, máximo, outra? Qualquer um pode ser inadequado. Como sempre, o bom senso é a única resposta.
quarta-feira, 22 de junho de 2016
Perguntas frequentes em bioestatística #15. E quando as regras da estatística não se parecem aplicar?
A seguinte mensagem é a décima quinta comunicação da série Perguntas
Frequentes em Bioestatística, da autoria de membros do Laboratório de
Bioestatística e Informática Médica da Faculdade de Medicina da Universidade de
Coimbra. Pretende-se fomentar uma discussão sobre as melhores práticas
estatísticas na área da saúde.
Miguel Patrício, Francisco Caramelo
A Estatística é um mundo complexo de regras e excepções, com diferentes
estratégias para lidar com o mesmo problema e muitos avisos sobre o que é pouco
aconselhável fazer-se. É frequentemente difícil desbravar o caminho no meio dos
dados colhidos e conseguir extrair conclusões dos mesmos. Em simultâneo, é
comum a noção (errada) que torturando os dados se pode sempre descobrir algum
padrão ou extrair alguma informação apelativa. Esta forma de pensar é, mais do
que se gostaria de admitir, profícua no mundo da investigação - de facto, após
a recolha dos dados existe a ideia que é quase sempre possível efectuar
diferentes análises estatísticas, obter algum valor-p interessante do ponto de
vista da publicação (tipicamente, p<0.05) e construir uma narrativa. Inverte-se
assim a lógica do método científico, em que o ponto de partida é uma questão,
se recolhem dados para responder a esta e os mesmos são analisados para se
obter a resposta. Deste modo, a colocação a
posteriori de perguntas, após a recolha dos dados, constitui uma forma
errada de construir Ciência e é fonte de inúmeros erros. É aliás um dos
factores que contribui para erodir a credibilidade das publicações científicas[1].
Tem havido uma grande discussão sobre a credibilidade da ciência, das
revistas e do sistema de peer-review.
São sobejamente conhecidos exemplos de autores que conseguem publicar, em
revistas de reputação pouco sólida, artigos com conteúdo jocoso[2].
O problema de se publicar o impublicável afecta também melhores revistas, em
que os editores e revisores muitas vezes não estão avisados para erros básicos
como o que se referiu em cima, de colocação de uma pergunta a posteriori[3] ou
para outros de carácter estatístico ou metodológico. De facto, com boa ou má
intenção, muitas publicações têm erros crassos que podem ser evitados tendo-se
em conta princípios básicos da Estatística (ou, com igual propriedade, do Método
Científico e do bom senso) como:
- As perguntas têm de ser colocadas a priori, antes da recolha dos dados. A análise estatística deve ser feita tendo as perguntas previamente colocadas em mente[4];
- A inferência estatística (por outras palavras, o cálculo de valores-p[5]) deve ser feita apenas quando fizer sentido. Deve-se ser parcimonioso, pois o recurso a muitos testes estatísticos obriga a correcções de comparações múltiplas[6];
- O tamanho da amostra deve ser suficientemente grande se se pretende fazer inferência. A razão é simples: para se poder inferir algo é preciso ter confiança nessa inferência - é preciso ser convincente. Dificilmente se consegue ser convincente com tamanhos amostrais como n=3. Há fórmulas para calcular o tamanho amostral[7];
- O tamanho do efeito deve ser objecto de discussão independentemente do significado estatístico[8].
Há muitas outras regras, ditadas pela Estatística, pelo Método Científico
ou pelo bom senso, que se poderiam acrescentar à lista em cima. Como sempre
acontece quando há muitos cuidados a ter em conta nalguma tarefa, torna-se
difícil, mesmo para a pessoa mais bem intencionada, tomar outra posição que não
seja ficar bloqueado ou avançar de forma temerária. Em paralelo, para quem
ensina Estatística[9],
colocam-se também desafios complicados - reduzir a complexidade de uma
disciplina a algumas horas implica fazer escolhas como apresentar sempre
exemplos simples, desenhos de estudo claros, questões em que a resposta seja
linear. A realidade, porém, é muito mais rica, complicada e não linear. Nalguns
casos, aparenta chocar com as regras da Estatística. Por exemplo, é frequente
que quem trabalha com animais se queixe de não poder ter um tamanho amostral
grande. E, se relativamente a isso a Estatística é clara (para se fazer
inferência é preciso calcular o tamanho amostral a priori), a prática vai noutra direcção - raramente se deixa de
fazer um trabalho por considerações sobre o tamanho amostral. É também comum
apresentarem-se valores-p em situações que não faz sentido. Se nalgumas
revistas já começa a ser colocado em causa o foco excessivo no valor-p[10],
este ainda é necessário para conseguir publicações com impacto na maioria das
áreas.
A aparente ou real falta de consenso e harmonia entre as exigências da
Estatística (e do bom senso) e as exigências do sucesso académico levam a que
facilmente as primeiras sejam abandonadas ou deturpadas. A persistência em
erros comuns é ainda banal, embora vá havendo cada vez maior discussão e
esforço para depurar a Ciência. Em particular, vê-se com assustadora
frequência:
- a indefinição da questão de investigação;
- o recurso a um número excessivo de testes estatísticos num mesmo trabalho, sem recurso a correcção para comparações múltiplas;
- a interpretação abusiva do valor-p;
- o recurso a testes paramétricos quando deveriam ser não paramétricos;
- más representações gráficas dos resultados[11], que induzem a interpretações erradas
Urge procurar caminhos que compatibilizem o rigor da Estatística e do
Método Científico com as práticas académicas. Se o rigor é inegociável, ou se
alteram as práticas na sua substância ou estas terão de ser reinterpretadas, de
forma a que explicitamente se afirme os limites da sua validade. Nesse sentido,
há algumas ideias que poderão ser úteis:
- Qualquer trabalho de índole estatístico deverá ter duas fases: uma fase de planeamento e uma fase de concretização. Na primeira fase, terá de definir-se claramente qual é a questão de investigação a que se pretende responder. Tudo o resto ficará subordinado a esta questão. Desta forma, a análise dos dados obtidos é determinada claramente pela questão de investigação, que não faz sentido definir a posteriori;
- É importante distinguir trabalhos exploratórios ou descritivos de trabalhos confirmatórios. Nos últimos pretende-se responder a uma questão muito específica, sendo o foco colocado na inferência. Nos primeiros pretende-se fazer um trabalho meramente descritivo (sem desprimor para a sua importância) ou procurar questões que possam ser posteriormente reanalisadas num trabalho confirmatório. Em trabalhos confirmatórios é fundamental fazer o cálculo do tamanho da amostra. Não sendo isto feito, o trabalho é automaticamente exploratório ou descritivo, não fazendo sentido calcular valores-p no seu sentido usual[12];
- O valor-p, como interpretado no sentido usual, apenas deverá ser calculado quando se pretenda fazer inferência estatística. Para esse efeito, deverá ter-se tido em conta cálculos do tamanho amostral. Mais ainda, o valor-p não deverá ser apresentado sem que, em conjunto, se apresentem medidas descritivas. De facto, é importante distinguir entre significância estatística e significância biológica (ou clínica) - o valor-p apenas se refere à primeira[13];
- Nalguns casos é possível calcular o valor-p sem se ter calculado primeiro o tamanho da amostra. Assim, mesmo em estudos exploratórios ou descritivos é aceitável a apresentação de valores-p. Porém, o significado dos mesmos devem ser clarificados: não se pretendendo fazer inferência, o valor-p serve como uma medida de tamanho do efeito, sendo meramente descritivo. Neste sentido, ter-se p<α não tem o significado usual de se ter significância estatística[14], ou seja, de se poder concluir algo relativamente à população. A interpretação deverá ser diferente: quanto mais pequeno for o valor-p, maior será o tamanho do efeito que se observa.
- É possível fazer muitos testes estatísticos num mesmo trabalho, mas terá de se recorrer a correcções para comparações múltiplas ou interpretar os valores-p obtidos no sentido exposto no último ponto - como sendo uma medida do tamanho do efeito.
Na verdade, as regras da Estatística, do Método Científico e do bom senso
deverão aplicar-se sempre. Compatibilizar as mesmas com as práticas exigidas
para se obter sucesso académico pode ser difícil, mas ou é possível ou o
sucesso será imerecido. Uma transferência de saber transparente clarificando os
aspectos anteriormente discutidos também ajuda o leitor a julgar de forma
crítica os achados em cada trabalho.
[1]
A este respeito, vale a pena ler o artigo: Ioannidis JPA (2005) Why Most
Published Research Findings Are False. PLoS Med 2(8): e124. doi:
10.1371/journal.pmed.0020124 ou o artigo “Estimating the reproducibility of psychological
science”: Open Science Collaboration, Science 349, aac4716 (2015). DOI: 10.1126/science.aac4716.
[2] Ver, por exemplo, o seguinte artigo
publicado por personagens dos Simpsons http://www.sciencealert.com/two-scientific-journals-have-accepted-a-study-by-maggie-simpson-and-edna-krabappel ou um artigo com linguagem imprópria em http://www.vox.com/2014/11/21/7259207/scientific-paper-scam.
[3] Um exemplo famoso da colocação de uma
pergunta a posteriori (que
estatisticamente se traduz pela necessidade de efectuar uma correcção para
comparações múltiplas) é explicado pelo autor de um artigo que proclamava
mostrar que comer chocolate preto ajuda a emagrecer. Na verdade, a colocação da
questão de investigação a posteriori
foi propositado e teve como objectivo demonstrar que este é um erro comum, como
explica o próprio autor do artigo aqui: http://io9.gizmodo.com/i-fooled-millions-into-thinking-chocolate-helps-weight-1707251800.
[5] O cálculo de um valor-p é efectuado tendo
em conta a amostra e a população. Por outras palavras, quando se aplica um
teste estatístico a dados amostrais, calcula-se um valor-p. Quando este é
inferior ao nível de significância (tipicamente α=0.05) rejeita-se a hipótese
nula para toda população. Por exemplo, se ao comparar níveis médios de
colesterol entre amostras de dois grupos, se obtiver p<α, então pode-se
inferir que há diferenças entre as médias populacionais dos níveis de
colesterol dos dois grupos. A partir das amostras dos grupos infere-se o que
acontece na população.
[8] Ver Sullivan, G. M., & Feinn,
R. (2012). Using Effect Size—or Why the P Value Is Not
Enough. Journal of Graduate Medical Education, 4(3), 279–282.
http://doi.org/10.4300/JGME-D-12-00156.1.
[9] São comuns as queixas do ensino da Estatística
ser muito desfasado da realidade com que o investigador se depara. Descontadas
as naturais faltas de perfeição dos professores da disciplina, até certo ponto
tal desfasamento deve-se à realidade exigir um grau de complexidade que
transvasa aquilo que se pode ensinar em poucas horas. Porém, também tem a ver
com um desrespeito generalizado que se verifica, no mundo da Ciência, pelo
Método Científico. Se cabe ou não à Estatística - ou apenas à Estatística - procurar
resolver este último aspecto é discutível.
[10] Não se coloca aqui em causa a
importância do valor-p, mas sim que o mesmo seja excessivamente calculado e
valorizado: ver http://laboratoriobioestatistica.blogspot.pt/2015/05/p-value-o-grande-enganador-ou-como.html. Vale também a pena ler o artigo seminal Johnson,
D. (1999). The Insignificance of Statistical Significance Testing. The
Journal of Wildlife Management, 63(3), 763-772. doi:1. Retrieved from http://www.jstor.org/stable/3802789
doi:1.
[11] Por exemplo, apesar da sua quase
omnipresença, o uso de gráficos de barras para representar variáveis
quantitativas deve ser desencorajado, ver por exemplo Streit M, Gehlenborg N.
Bar charts and box plots. Nat Methods 2014; 11:117.
[12] Por sentido usual, pretendemos
dizer no sentido inferencial. Por outras palavras, a menos que o estudo seja
confirmatório, o objectivo não deverá ser verificar se uma determinada
hipótese, colocada relativamente a uma população, pode ou não ser rejeitada.
[14] Não se pode, desta forma, afirmar haver
diferenças estatisticamente significativas. É possível explicitar qual foi o
valor-p obtido, mas tendo em conta que este é uma medida do tamanho do efeito e
não uma indicação de podermos ou não inferir algo acerca da população.
Subscrever:
Mensagens (Atom)